这篇文章发布于 2021年02月16日,星期二,17:36,归类于 JS API。 阅读 43391 次, 今日 5 次 6 条评论
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=9835
本文欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可以联系授权。

HTML字符串转DOM方法有好几个,这里盘点下各个方法的优缺点,以及关于DOM的其他一些细节。
一、方法盘点
1. innerHTML
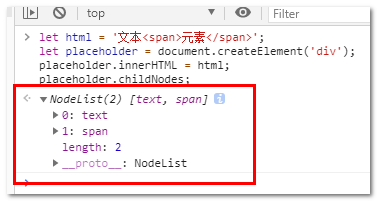
let html = '文本<span>元素</span>';
let placeholder = document.createElement('div');
placeholder.innerHTML = html;
let nodes = placeholder.childNodes;
其中nodes包含了所有的节点信息。
| 安全性 | ✔ | script脚本不会执行 |
|---|---|---|
| 任意节点 | ✘ | 不合法的节点无法转换,例如p标签里面嵌套div。除非使用<template>元素,本文后面会有介绍。 |
| 兼容性 | ★★★★ | IE6+均支持 |
2. insertAdjacentHTML
let html = '<span>元素</span>';
let placeholder = document.createElement('div');
placeholder.insertAdjacentHTML('afterbegin', html);
// 如果HTML是单个闭合HTML标签,可以直接使用firstElementChild直接返回
let node = placeholder.firstElementChild;
insertAdjacentHTML方法可以指定HTML字符插入的位置,支持4个方位,特性盘点参见下表:
| 安全性 | ✔ | script脚本不会执行 |
|---|---|---|
| 任意节点 | ✘ | 不合法的节点无法转换,例如div标签里面嵌套tr |
| 兼容性 | ★★★ | IE6+支持,IE10-不支持table相关的标签,例如tr, td, thead等元素。 |
3. DOMParser
使用示意:
nodes = new DOMParser().parseFromString(html, 'text/html').body.childNodes;
DOMParser()可以解析HTML字符串,不仅普通HTML字符串,传统的XML字符串,SVG字符串都可以解析。我们还可以使用DOMParser()方法反转义HTML标签,详见这篇文章“巧用DOM API实现HTML字符的转义和反转义”。
DOMParser的相关特性如下表所示:
| 安全性 | ✔ | script脚本不会执行 |
|---|---|---|
| 任意节点 | ✘ | 可以作为body子元素的标签才可以解析,例如 '<tr>text</tr>' 就无法解析出<tr>元素。 |
| 兼容性 | ★★ | IE 10+, Safari 9.1+ |
4. Range
此方法使用示意:
elements = document.createRange().createContextualFragment(html).children;
这里使用了chidlren属性示意,可以返回HTMLCollection,元素合集,忽略文本。
特性如下:
| 安全性 | ✘ | script脚本会执行,使用时候需要注意 |
|---|---|---|
| 任意节点 | ✘ | 此API可以指定合适的上下文,此时才能方便解析。 |
| 兼容性 | ★★ | IE 10+, Safari 9+ |
//zxx: 如果你看到这段文字,说明你现在访问是体验糟糕的垃圾盗版网站,你可以访问原文获得很好的体验:https://www.zhangxinxu.com/wordpress/?p=9835(作者张鑫旭)
二、DOM转换合法性的处理
上面的DOM转换方法,对于一些特殊的标签,尤其是表格相关的元素,直接使用可能是无效的。
例如下面的:
let placeholder = document.createElement('div');
placeholder.innerHTML = `<tr><td>zhangxinxu.com</td></tr>`;
console.log(placeholder.firstElementChild); // 结果是 null
div元素中插入tr标签相关的HTML字符串,这段HTML会认为是不合法的,从而不会转换为tr元素。
此时需要通过创建table元素来返回,例如:
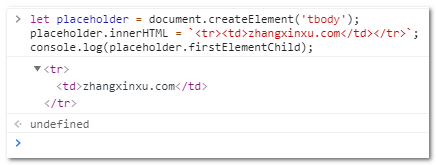
let placeholder = document.createElement('tbody');
placeholder.innerHTML = `<tr><td>zhangxinxu.com</td></tr>`;
console.log(placeholder.firstElementChild); // 结果是 tr 元素
上面这段代码运行效果如下截图所示:
createContextualFragment
createContextualFragment方法也是类似的处理,需要指定tbody元素作为Range区域上下文。
代码示意:
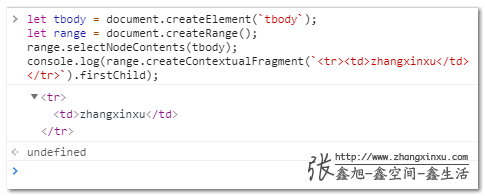
let tbody = document.createElement(`tbody`); let range = document.createRange(); range.selectNodeContents(tbody); console.log(range.createContextualFragment(`<tr><td>zhangxinxu</td></tr>`).firstChild);
运行效果如下截图所示:
template
还有一种方法不需要考虑上下文,即可实现任意标签HTML元素的DOM转换,这个元素就是HTML5 <template>元素。
JavaScript代码使用示意:
let template = document.createElement('template');
template.innerHTML = `<tr><td>禁止公众号转载</td></tr>`;
console.log(template.content.lastChild);
同样可以返回<tr>元素,例如在Chrome console控制台运行的结果:

<template>元素虽然好使,但是兼容性不足,IE浏览器不支持,关于该元素更多信息可以参考我多年前写的这篇文章“HTML5 <template>标签元素简介”。
三、关于HTML字符串中JS的执行
createContextualFragment方法会执行内联的script js代码,为了安全起见,这个方法尽量不要使用,避免被攻击,除非当前的需求就是希望里面的JS代码一起支持。
而其他的innerHTML方法、或者insertAdjacentHTML方法都不用担心JS会被支持,例如:
let placeholder = document.createElement('div');
placeholder.innerHTML = `<div><script>alert('鑫空间');</script></div>`;
let node = placeholder.firstElementChild;
document.body.appendChild(node); // 不会有alert提示
但是,使用HTML属性设置的JS代码是会运行的,例如:
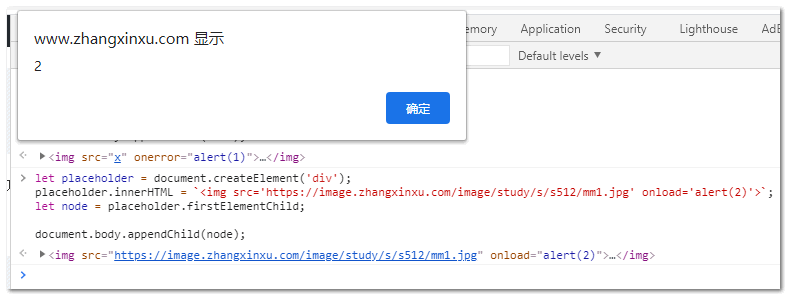
let placeholder = document.createElement('div');
placeholder.innerHTML = `<img src='x' onerror='alert(1)'>`;
let node = placeholder.firstElementChild;
document.body.appendChild(node);
上面的代码在Chrome浏览器下就会执行alert(1),其他类似的属性还有 onload,例如上面代码onerror换成onload,src改成正常的URL地址,在Chrome控制台跑一下,就会看到代码执行了。
我自己就测了下,截图如下:
因此,在进行HTML字符串转DOM时候,记得过滤onload和onerror属性,尤其是第3方的HTML字符串,一定要注意安全,防止XSS攻击。
四、关于转换的性能
测试数据源自这里:jsPerf benchmark,下面是结果:
Range.createContextualFragment()— winner (Firefox浏览器中最快)Element.insertAdjacentHTML()— winnerElement.innerHTML— winnerDOMParser.parseFromString()— 90% slower
结论是DOMParser方法性能最差。
不过上面的测试结果对我们日常开发影响不大,因为通常的HTML解析都是很轻量的,性能这块没有本质区别。除非是,那种几百K的HTML或者上M兆的SVG文件的解析。
五、总结和结语
innerHTML方法最朴实无华,性价比最高,如果不考虑IE浏览器,直接使用template元素再innerHTML,任意HTML标签元素都可以转换成DOM。
注意安全,防止XSS攻击。
DOMParser方法性能稍差,不过非大规模应用场景不能作为技术选型的考量因素。
以上就是本文全部内容,希望可以对大家的学习有所帮助。
欢迎转发、欢迎分享、也欢迎补充相关知识点,比心感谢。
![]()
参考文章
本文参考自:Create a DOM node from an HTML string
修正了原文部分错误,补充了若干截图信息。
本文为原创文章,欢迎分享,勿全文转载,如果实在喜欢,可收藏,永不过期,且会及时更新知识点及修正错误,阅读体验也更好。
本文地址:https://www.zhangxinxu.com/wordpress/?p=9835
(本篇完)
- 小tip: DOM appendHTML实现及insertAdjacentHTML (0.376)
- 介绍两个DOM新方法setHTMLUnsafe和getHTML (0.336)
- 巧用DOM API实现HTML字符的转义和反转义 (0.288)
- DOMParser和XMLSerializer两个API简介 (0.232)
- jquery之append与insertBefore使用实例 (0.144)
- 见多识广,介绍Web开发中current开头的一些API属性 (0.144)
- gitee上撸了个类似飞书OKR输入框的@提及项目 (0.144)
- 从今天开始,请叫我Node文本节点处理大师 (0.144)
- 今日学习CSS文本自定义高亮API (0.144)
- js面向数据编程(DOP)一点分享 (0.088)
- jQuery诞生记-原理与机制 (RANDOM - 0.016)

 我的应用
我的应用 我的应用
我的应用{kind=link}
document.createFragment 去哪了?
DOMPurifer
永远需要过滤。即使是javascript:;或者onclick等都危险。
最近用做邮件预览需求的时候, 才知道 DOMParser , 用来解析邮件内容为 HTML 插入到 iframe 中, 挺好用的
DOMParse 很适合用来预处理页面HTML,比如所有图片转懒加载,重包装等
右上角挂着vpn的广告,这样不会被查吗?
IE浏览器总是会拖后腿 哈哈