这篇文章发布于 2021年01月21日,星期四,00:21,归类于 JS API。 阅读 26682 次, 今日 15 次 11 条评论
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=9770
本文欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可以联系授权。

一、HTML字符的转义
不转弯,HTML字符转义有更简单更容易记忆的方法,如下:
let textNode = document.createTextNode('<span>by zhangxinxu</span>');
let div = document.createElement('div');
div.append(textNode);
console.log(div.innerHTML);
也就是把HTML内容作为文本节点的textContent内容,然后使用普通元素的innerHTML属性返回下就可以了。
上面代码输出的结果是:
<span>by zhangxinxu</span>
大家可以复制上面代码在控制台跑一下,例如下图就是我在Chrome浏览器中运行的结果:
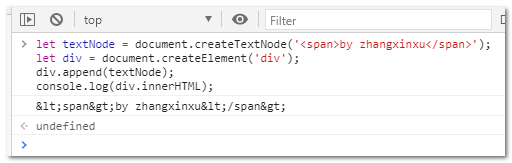
二、HTML字符的反转义
这个需要用到的DOM API就相对稀罕了一点,使用DOMParser API。
代码示意:
let str = '<span>by zhangxinxu</span>'; let doc = new DOMParser().parseFromString(str, 'text/html'); console.log(doc.documentElement.textContent);
结果就是:
<span>by zhangxinxu</span>
眼见为实,运行截图参见下方:
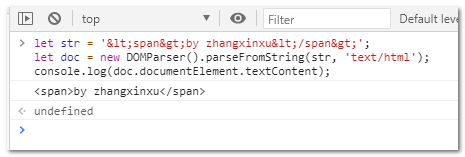
然后还有一种方法是借助<textarea>元素,这是IE浏览器时代常用的一种方法,代码示意如下:
let textarea = document.createElement('textarea');
textarea.innerHTML = '<span>by zhangxinxu</span>';
console.log(textarea.childNodes[0].nodeValue);
结果也是一样的,转义的HTML标签都反转义回来了:
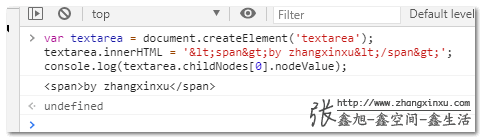
//zxx: 如果你看到这段文字,说明你现在访问是体验糟糕的垃圾盗版网站,你可以访问原文获得很好的体验:https://www.zhangxinxu.com/wordpress/?p=9770(作者张鑫旭)
三、DOM API方法的缺点
DOM API方法利用了浏览器的能力,更容易上手,转义结果也更安全,但是有个不足,那就是只能在浏览器上下文环境中使用。例如,如果是Service Workers环境,或者是Node.js环境中,这个方法就不行了,只能使用传统的字符串处理方法了。
传统的字符串处理代码示意:
/**
* 转义HTML标签的方法
* @param {String} str 需要转义的HTML字符串
* @return {String} 转义后的字符串
*/
var funEncodeHTML = function (str) {
if (typeof str == 'string') {
return str.replace(/<|&|>/g, function (matches) {
return ({
'<': '<',
'>': '>',
'&': '&'
})[matches];
});
}
return '';
};
/**
* 反转义HTML标签的方法
* @param {String} str 需要反转义的字符串
* @return {String} 反转义后的字符串
*/
var funDecodeHTML = function (str) {
if (typeof str == 'string') {
return str.replace(/<|>|&/g, function (matches) {
return ({
'<': '<',
'>': '>',
'&': '&'
})[matches];
});
}
return '';
};
四、爽言爽语
最近一周在更换网站备案,目前已经备案好了,网站访问将会恢复正常,文章更新也会回到正常频率。
OK,这就是本文全部内容啦!
感谢大家支持,如果觉得相关知识还真有用,欢迎转发到朋友圈,如果是PC端访问,则左侧或下方应该可以看到微信图标按钮,点击、扫码分享,感谢感谢!
![]()
本文为原创文章,欢迎分享,勿全文转载,如果实在喜欢,可收藏,永不过期,且会及时更新知识点及修正错误,阅读体验也更好。
本文地址:https://www.zhangxinxu.com/wordpress/?p=9770
(本篇完)
- 盘点HTML字符串转DOM的各种方法及细节 (0.355)
- 原来浏览器原生支持JS Base64编码解码 (0.287)
- DOMParser和XMLSerializer两个API简介 (0.273)
- 从今天开始,请叫我Node文本节点处理大师 (0.205)
- 小tips: JS DOM innerText和textContent的区别 (0.184)
- 几个常见功能重合DOM API的细节差异 (0.102)
- gitee上撸了个类似飞书OKR输入框的@提及项目 (0.102)
- js面向数据编程(DOP)一点分享 (0.082)
- github上html5shiv项目readme.md部分的翻译 (0.082)
- 学习了,CSS中内联SVG图片有比Base64更好的形式 (0.082)
- JS与条形码的生成 (RANDOM - 0.082)

 我的应用
我的应用 我的应用
我的应用{kind=link}
小白问一下这个使用的场景有哪些
XSS防御中的HTML转义过滤
function encode(str) {
var div = document.createElement(‘div’);
div.textContent = str;
return div.innerHTML;
}
function decode(str) {
var div = document.createElement(‘div’);
div.innerHTML = str;
return div.textContent;
}
此处decode小心XSS注入
JSX 浏览器端的渲染就是运动的这个方案
大佬出来创业了吗?
没
图片挂了
只做纯js前端的我感觉非常实用哈哈
是好办法。
就是网上许多简易的字符串替换HTML转义做得太粗糙(典型如连续空格)无法处理。想必完整替换处理也是个头疼事情。尽管,对于避免一些(意外)HTML注入是有意义的。
这里用DOM处理,思路奇巧,效果良好,同时代码还特别短,前面大多数情境下够用。(毕竟后端可以不计成本,别人写好的工具随便用)
分享正爽????????